Project / 07
Cross-Asset Price Prediction - multi-task learning
University of Waterloo WiM Directed Reading Program. A three-person mentored project that builds a shared-bottom multi-task neural network to forecast several assets jointly, benchmarks it against linear regression and single-task neural nets, and finds that multitask learning bought efficiency rather than accuracy on noisy next-day prices.
The problem
Most introductory ML forecasting predicts one number: the next price of one asset. But prices across equities, commodities, fixed income, and currencies are interconnected through shared market and economic forces, so a model that learns several at once can, in principle, exploit those relationships instead of relearning them for each asset. That is the premise of multi-task learning (MTL): a network with a shared body and one output head per task, trained on a single joint loss so the tasks regularize each other.
The University of Waterloo WiM Directed Reading Program set out to test that premise on real markets. Over a mentored term, our team built a shared-bottom MTL network to forecast several assets jointly and compared it head-to-head against a linear-regression baseline and single-task neural networks. The honest question was not "can we make MTL run," but "does jointly learning related assets actually beat modeling them separately?"
My role
This was a three-person mentee team - Hany Jiang, Momina Butt, and Bhavika Dindyal - working under a mentor (Hao Quan) during the Winter 2026 term and presenting at the end of March. The repository linked here is the cohort's shared program space: the syllabus, the weekly readings, and the reference notebooks.
The program was reading-led, pairing each week's reading with a coding assignment - Géron's Hands-on Machine Learning for practical ML, ISLP chapter 10 for the deep-learning grounding, Brownlee's Deep Learning for Time Series Forecasting, and Caruana's 1997 Multitask Learning paper for the core idea. The hands-on work spanned the full pipeline: cleaning and aligning multi-asset data, engineering features, and building and benchmarking the linear, single-task, and multi-task models.
System design
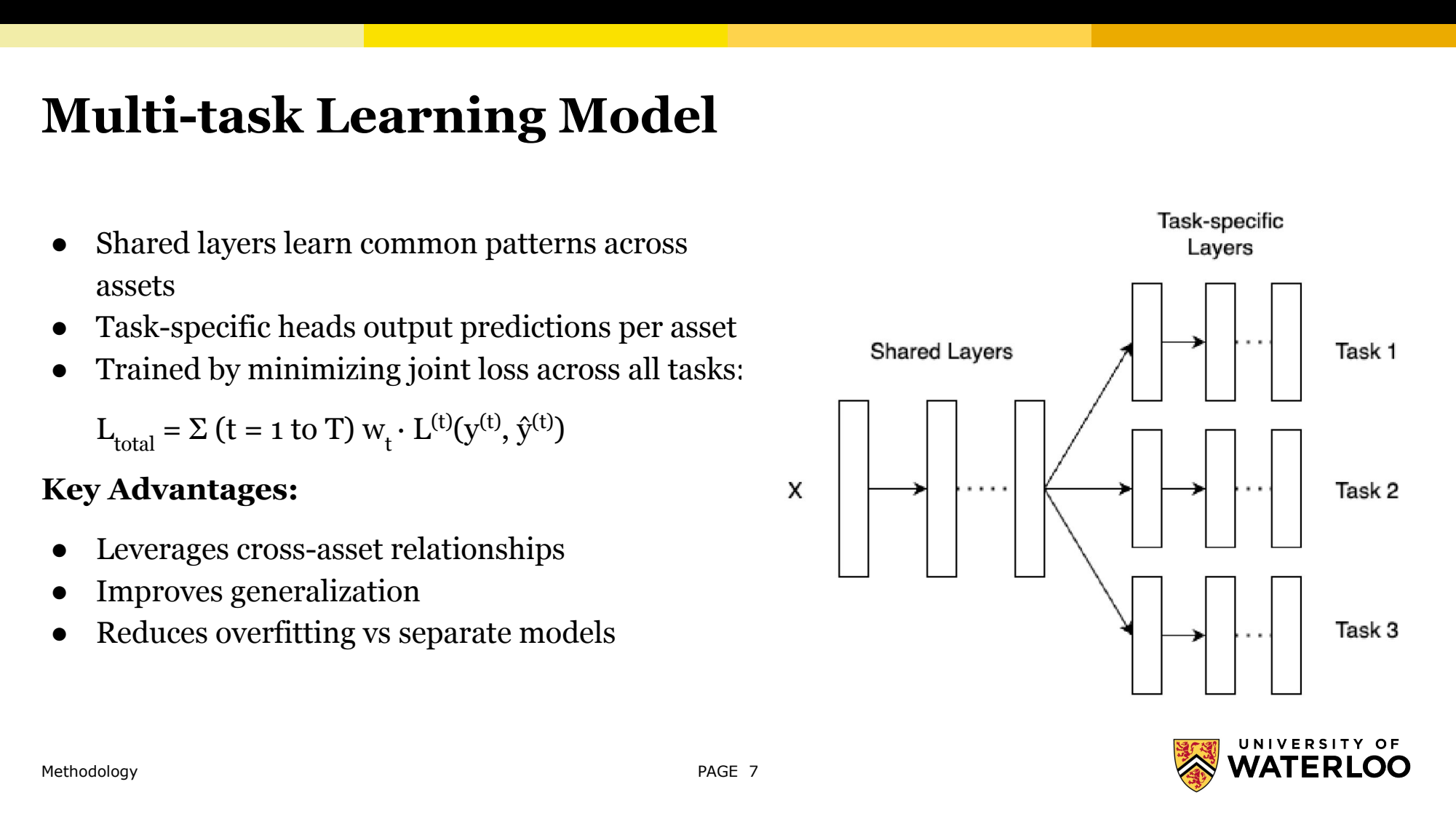
The multi-task model from our final presentation: input features pass through shared layers that learn cross-asset structure, then split into task-specific heads that each predict one asset, trained on a single joint loss summed across tasks.
The study compares three models on the same data. A linear-regression baseline predicts each target as a linear combination of features by minimizing squared error - simple, fast, and interpretable. A feedforward neural network (FNN) adds hidden layers to capture nonlinear interactions. The multi-task model is a shared-bottom FNN: shared layers learn patterns common across assets, and task-specific heads each output one asset's prediction, trained by minimizing a single joint loss that sums each task's loss. The appeal, following Caruana, is that a shared representation should improve generalization and reduce overfitting versus training one network per asset.
Most of the engineering was in preprocessing, which matters more in a multi-task setting because every task has to stay consistent. Raw financial series are noisy and uneven, so the pipeline aligns timestamps across assets, fills missing values by interpolation or forward-fill, and scales features (MinMax or standardization) so a large-magnitude asset does not dominate learning. The series are then structured into supervised examples with a sliding window - past W observations predict the next step, with W chosen on validation. On top of raw prices, the team engineered features to capture market dynamics: OHLC prices, log returns, rolling volatility, and technical indicators (SMA, RSI, MACD).
Key technical decisions
- Three models on identical data. Linear regression, a single-task FNN, and a shared-bottom multi-task FNN were trained and evaluated the same way, so the comparison isolates the effect of architecture and sharing rather than setup. The simple baseline is there precisely to keep the neural models honest.
- Shared-bottom multi-task architecture. Shared dense layers feed task-specific heads, one per asset, under a weighted joint loss. The hypothesis is that related tasks act as mutual inductive bias, so sharing structure should help generalization and curb overfitting relative to separate networks.
- Preprocessing as the real lever. Consistency across assets is critical in a multi-task setting: aligned timestamps, interpolated or forward-filled gaps, and common scaling so no single asset dominates. The team found that strong preprocessing was a large part of why even the simplest model performed well.
- Feature engineering over raw price. Raw prices alone underrepresent behavior, so the inputs add log returns, rolling volatility, and SMA/RSI/MACD indicators to encode trend, momentum, and variability.
- Sliding-window, next-step targets on a time-ordered split. Past W observations predict the next day, split by time to avoid look-ahead leakage - which also surfaces just how noisy a next-day target really is.
Results
The clearest result was a humbling one: multi-task learning did not improve accuracy. On the held-out test set, the simple linear regression was the most accurate and by far the fastest, and neither neural model came close to it:
- Linear regression - RMSE ~15.7, MAE ~9.2, ~15 s runtime (best on both accuracy and speed)
- MTL-FNN (shared-bottom) - RMSE ~31.2, MAE ~21.0, ~870 s
- Single-task FNN - RMSE ~39.1, MAE ~25.6, ~8,250 s
Where MTL did win was efficiency. The shared-bottom network clearly beat the plain single-task FNN on accuracy, and it trained in roughly 870 seconds against about 8,250 for the separate FNNs - collapsing several models into one shared network was multitask learning's main practical payoff here. So the takeaway was not "MTL is better," but "MTL gave a much cheaper neural model, while a linear model was good enough to beat both."
The deliverable was this benchmark plus a final presentation walking through the motivation, the three methods, the preprocessing pipeline, the results, and an honest analysis of why the fancier model lost. More than any single number, the value of the program was the progression - from fetching one asset's history and plotting it, to a controlled comparison where a negative result is reported plainly and explained.
What I would do differently
The most useful part of the project was diagnosing why MTL underperformed, and that points straight at what I would change. The assets may simply not be similar enough - gold and equities are driven by different forces, so the shared layers had little common structure to learn - and joint training can cause negative transfer, where tasks interfere and hurt each other. The strong showing of linear regression also suggests the usable signal was mostly linear, so the extra capacity of the neural models mostly added variance.
I would also give the neural models a fairer shot. About 1,250 trading days is very little data once rolling windows and train/test splits are applied, and a next-day price target is dominated by unpredictable events, so I would extend the history, predict smoother targets such as multi-day returns or volatility, and lean harder on regularization.
Finally, I would replace the backbone. A feedforward network cannot model temporal order well, which is a poor fit for time series; swapping in sequence models - LSTM, GRU, temporal CNNs, or transformers - inside the same multi-task framework is the natural next step, and the one our presentation flagged as future work.